第十一章:批處理
帶有太強個人色彩的系統無法成功。當最初的設計完成並且相對穩健時,真正的考驗才剛開始:此後會有許多持不同觀點的人做出各自的實驗。
高德納
到目前為止,本書大部分內容都圍繞著 請求(request) 與 查詢(query) 以及對應的 響應(response) 或 結果(result) 展開。現代很多資料系統都預設採用這種處理方式:你發出請求或指令,系統儘快給出答案。
網頁瀏覽器請求頁面、服務呼叫遠端 API、資料庫、快取、搜尋索引,以及很多其他系統都如此運作。我們稱這類系統為 線上系統(online systems)。它們通常以響應時間作為主要效能指標,並且往往需要良好的容錯能力來保證高可用。
但有時候,你需要執行的計算比一次互動式請求大得多,或者要處理的資料量遠超單次請求能承載的範圍。例如訓練 AI 模型、把海量資料從一種形式轉換成另一種形式、或者在超大資料集上做分析計算。我們把這類任務稱為 批處理(batch processing) 作業,有時也稱為 離線系統(offline systems)。
批處理作業讀取一批輸入資料(只讀),並生成一批輸出資料(每次執行都從頭生成)。它通常不會像讀寫事務那樣原地修改資料。因此,輸出是由輸入推匯出的 派生資料(derived data)(見“記錄系統與派生資料”):如果不滿意輸出,你可以直接刪除它,修改作業邏輯,再跑一遍即可。把輸入視為不可變並儘量避免副作用(例如直接寫外部資料庫),不僅有助於效能,也帶來其他好處:
如果你在程式碼中引入了 bug 導致輸出錯誤或損壞,可以直接回滾程式碼並重跑作業,輸出就會恢復正確。更簡單的做法是把舊輸出保留在另一個目錄,直接切回舊版本。多數物件儲存與開放表格式(見“雲資料倉庫”)都支援這種能力,通常稱為 時間旅行(time travel)。大多數支援讀寫事務的資料庫不具備這種特性:如果錯誤程式碼把壞資料寫進資料庫,僅回滾程式碼並不能修復已寫入的資料。能夠從錯誤程式碼中恢復的能力被稱為 容忍人為失誤 1。
因為回滾容易,功能開發能比“犯錯會造成不可逆損害”的環境更快推進。這個 最小化不可逆性 的原則對敏捷開發非常有益 2。
同一組檔案可以作為多種作業的輸入,包括監控類作業:例如計算指標、驗證輸出是否符合預期(如與上一次結果比較並度量偏差)。
批處理框架能更高效地利用計算資源。雖然也可以用 OLTP 資料庫和應用伺服器等線上系統做批處理,但資源成本通常顯著更高。
批處理也有挑戰。多數框架中,作業只有在整體完成後,其輸出才能被下游進一步處理。批處理也可能低效:輸入哪怕只變動一個位元組,也可能需要重算整個輸入資料集。儘管如此,批處理在大量場景中依然非常有用,我們會在“批處理用例”中回到這個話題。
批處理作業可能執行很久:幾分鐘、幾小時甚至幾天。很多作業是週期排程的(例如每天一次)。它的核心效能指標通常是吞吐量:單位時間能處理多少資料。有些批處理系統透過“中止並整體重啟”應對故障,也有些具備更細粒度容錯能力,可以在部分節點崩潰時仍讓作業完成。
Note
批處理的另一種替代形態是 流處理(stream processing):作業不會在“處理完輸入後結束”,而是持續監聽輸入,並在變化發生後很快處理。我們將在第十二章討論流處理。
線上處理與批處理的邊界並不總是清晰:一個執行很久的資料庫查詢,看起來也很像批處理過程。但批處理有一些獨特特性,使其成為構建可靠、可伸縮、可維護應用的重要積木。例如,它常在 資料整合(data integration) 中發揮作用,即把多個數據系統組合起來完成單一系統做不到的事。ETL(見“資料倉庫”)就是典型例子。
現代批處理深受 MapReduce 影響。Google 在 2004 年發表了這一批處理演算法 3,隨後 Hadoop、CouchDB、MongoDB 等開源系統都實現了它。MapReduce 是相對底層的程式設計模型,其能力不如資料倉庫中的並行查詢執行引擎成熟 4 5。它在誕生時確實讓商用硬體上的處理規模躍升一大步,但今天已大體過時,Google 內部也不再使用 6 7。
如今批處理更常透過 Spark、Flink 或資料倉庫查詢引擎完成。它們與 MapReduce 一樣高度依賴分片(見第七章)和並行執行,但快取與執行策略更成熟。隨著這些系統走向成熟,運維問題已大幅緩解,重點轉向可用性:資料流 API、查詢語言、DataFrame API 得到廣泛支援;任務與工作流編排也顯著進化。以 Hadoop 為中心的 Oozie、Azkaban 等排程器,正被 Airflow、Dagster、Prefect 這類更通用方案替代,它們可協調多種批處理框架與雲資料倉庫。
雲計算已無處不在。批處理儲存層也正在從 HDFS、GlusterFS、CephFS 這類分散式檔案系統(DFS)向 S3 等物件儲存遷移。BigQuery、Snowflake 這類可伸縮雲資料倉庫,正在模糊“資料倉庫”和“批處理系統”之間的邊界。
為了建立直覺,本章先從單機 Unix 工具示例出發,再擴充套件到分散式多機處理。你會看到,分散式批處理框架在很多方面很像作業系統:它也有排程器和檔案系統。隨後我們會討論編寫批處理作業的幾種處理模型,最後給出常見應用場景。
使用 Unix 工具的批處理
假設你有一臺 Web 伺服器,每處理一個請求就在日誌檔案末尾追加一行。例如,使用 nginx 預設訪問日誌格式,一行可能像這樣:
216.58.210.78 - - [27/Jun/2025:17:55:11 +0000] "GET /css/typography.css HTTP/1.1"
200 3377 "https://martin.kleppmann.com/" "Mozilla/5.0 (Macintosh; Intel Mac OS X
10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36"
(實際上這是一行,這裡為了閱讀方便換了行。)這一行包含了很多資訊。要正確解釋它,你需要日誌格式定義:
$remote_addr - $remote_user [$time_local] "$request"
$status $body_bytes_sent "$http_referer" "$http_user_agent"
這表示:UTC 時間 2025 年 6 月 27 日 17:55:11,伺服器收到來自客戶端 IP 216.58.210.78 對 /css/typography.css 的請求。使用者未認證,因此 $remote_user 是連字元(-)。響應狀態碼是 200(成功),響應體大小 3,377 位元組。瀏覽器是 Chrome 137,該檔案是從頁面 https://martin.kleppmann.com/ 引用而來。
看起來“解析日誌”有點樸素,但它在現代科技公司裡是核心能力之一,從廣告流水線到支付處理都大量依賴。事實上,這也是 MapReduce 與“大資料”浪潮快速興起的重要推動力。
簡單日誌分析
很多工具都能從日誌生成漂亮的網站流量報告。這裡為了練手,我們只用基礎 Unix 工具自己做一個。比如你想找出網站最受歡迎的五個頁面,可以在 shell 中這樣做:
cat /var/log/nginx/access.log | #1
awk '{print $7}' | #2
sort | #3
uniq -c | #4
sort -r -n | #5
head -n 5 #6- 讀取日誌檔案。(嚴格說這裡不需要
cat,可直接把檔案作為awk引數;但這樣寫更直觀看出線性管道。) - 以空白字元切分每行,只輸出第 7 個欄位,也就是請求 URL。上面的樣例中是
/css/typography.css。 - 按字典序對 URL 排序。某個 URL 若出現 n 次,排序後會連續出現 n 行。
uniq透過比較相鄰兩行是否相同來去重。-c讓它輸出計數:每個不同 URL 出現了多少次。- 第二次
sort按每行開頭的數字(-n)排序,並用-r逆序,出現次數最多的排在最前。 head只保留前 5 行(-n 5),丟棄其餘。
輸出大致如下:
4189 /favicon.ico
3631 /2016/02/08/how-to-do-distributed-locking.html
2124 /2020/11/18/distributed-systems-and-elliptic-curves.html
1369 /
915 /css/typography.css如果你不熟悉 Unix 工具,這條命令看起來可能有點晦澀,但它威力很強。它能在幾秒內處理 GB 級日誌,而且修改分析邏輯也非常方便:例如要排除 CSS 檔案,可把 awk 引數改成 '$7 !~ /\.css$/ {print $7}';若要統計訪問最多的客戶端 IP,把 awk 引數改成 '{print $1}' 即可。
本書篇幅有限,無法展開講 Unix 工具,但它們非常值得學。令人驚訝的是,僅靠 awk、sed、grep、sort、uniq、xargs 的組合,就能在幾分鐘內做出很多資料分析,並且效能相當好 8。
命令鏈與自定義程式
你也可以不用 Unix 管道,而寫個小程式完成同樣的事。比如用 Python:
from collections import defaultdict
counts = defaultdict(int) #1
with open('/var/log/nginx/access.log', 'r') as file:
for line in file:
url = line.split()[6] #2
counts[url] += 1 #3
top5 = sorted(((count, url) for url, count in counts.items()), reverse=True)[:5] #4
for count, url in top5: #5
print(f"{count} {url}")counts是散列表,記錄每個 URL 出現次數,預設值為 0。- 每行按空白字元切分,取第 7 個欄位作為 URL(Python 陣列從 0 開始,所以索引是 6)。
- 當前行對應 URL 的計數器加一。
- 按計數降序排序,取前五項。
- 列印前五項。
這個程式不如 Unix 管道簡潔,但可讀性也不錯,偏好取決於習慣。不過兩者除了語法差異,執行流程也很不一樣;在大檔案上執行時,這種差異會很明顯。
排序與記憶體聚合
Python 指令碼在記憶體裡維護了一個“URL -> 出現次數”的散列表。Unix 管道示例沒有這種散列表,而是透過排序把同一 URL 的多次出現排到一起。
哪種方法更好?取決於不同 URL 的數量。對多數中小網站而言,通常可以把所有不同 URL 及其計數器放進(比如)1GB 記憶體。這個作業的 工作集(working set)(需要隨機訪問的記憶體規模)只取決於不同 URL 的個數:即便一百萬條日誌都指向同一 URL,散列表也只存一個 URL 和一個計數器。工作集足夠小時,記憶體散列表很好用,筆記本都能跑。
但如果工作集大於可用記憶體,排序法就有優勢:它能高效使用磁碟。這與“日誌結構儲存”中的原理一樣:先在記憶體對資料塊排序並寫成段檔案,再把多個有序段合併成更大的有序檔案。歸併排序的順序訪問模式對磁碟很友好(見“SSD 上的順序寫與隨機寫”)。
GNU Coreutils(Linux)中的 sort 能自動把超記憶體資料溢寫到磁碟,並自動利用多核並行排序 9。這意味著前面的 Unix 命令鏈可以自然擴充套件到大資料集而不耗盡記憶體,瓶頸通常變成磁碟讀取輸入檔案的速率。
Unix 工具的一個侷限是它們只在單機執行。當資料大到單機記憶體或本地磁碟都放不下時,就需要分散式批處理框架。
分散式系統中的批處理
在前面的 Unix 示例中,單機有幾個協同元件在處理日誌:
- 透過作業系統檔案系統介面訪問的儲存裝置。
- 決定程序何時執行、如何分配 CPU 資源的排程器。
- 一串透過管道把
stdin/stdout連線起來的 Unix 程式。
分散式批處理框架也有對應元件。某種意義上,你可以把分散式處理框架看成“分散式作業系統”:它有檔案系統、有任務排程器,還有透過檔案系統或其他通道互相傳遞資料的程式。
分散式檔案系統
作業系統提供的檔案系統由多層組成:
- 最底層是塊裝置驅動,直接與磁碟互動,向上層提供原始塊讀寫。
- 塊層之上是頁快取,快取最近訪問塊以提升讀取速度。
- 塊 API 之上是檔案系統層,負責把大檔案切塊,並維護 inode、目錄、檔案等元資料。Linux 常見實現如 ext4、XFS。
- 最上層,作業系統透過統一 API(虛擬檔案系統,VFS)嚮應用暴露不同檔案系統,讓應用以統一方式讀寫底層不同實現。
分散式檔案系統(DFS)工作方式很類似:檔案被切成塊並分散到多臺機器。DFS 的塊通常比本地檔案系統大得多:HDFS 預設 128MB,JuiceFS 和許多物件儲存常用 4MB,而 ext4 預設塊通常是 4096 位元組。塊越大,需要維護的元資料越少,這對 PB 級資料非常關鍵;同時尋道開銷佔比也更低。
大多數物理儲存裝置不能做“部分塊寫入”,即使資料不足一個塊也得寫滿塊。DFS 的塊更大且通常構建在作業系統檔案系統之上,因此一般沒有這個約束。比如一個 900MB 檔案在 128MB 分塊下,會有 7 個 128MB 塊和 1 個 4MB 塊。
讀取 DFS 塊需要透過網路請求到持有該塊的叢集節點。每臺機器都執行守護程序,對外提供 API,使遠端程序能把本地檔案系統中的塊當作檔案讀寫。HDFS 把這些守護程序叫 DataNode,GlusterFS 叫 glusterfsd。後文統稱 資料節點(data node)。
DFS 也實現了“分散式版本”的頁快取。因為 DFS 塊作為檔案存放在資料節點本地,讀寫會經過資料節點作業系統,自帶記憶體頁快取,熱門塊會被快取在記憶體中。某些 DFS 還提供更多快取層,例如 JuiceFS 的客戶端快取和本地磁碟快取。
像 ext4/XFS 這樣的檔案系統會維護空閒空間、塊位置、目錄結構、許可權等元資料。DFS 同樣需要記錄“檔案塊分佈在哪些機器”“許可權如何”等資訊。Hadoop 使用 NameNode 維護叢集元資料;DeepSeek 的 3FS 使用元資料服務並把元資料持久化到 FoundationDB 之類鍵值儲存。
在檔案系統之上是 VFS。批處理系統裡最接近它的是 DFS 協議:批處理框架需要透過協議/介面來讀寫儲存。只要實現協議,就能作為可插拔儲存接入。例如 S3 API 已被 MinIO、Cloudflare R2、Tigris、Backblaze B2 等大量系統相容支援。具備 S3 支援的批處理系統通常可直接使用這些儲存。
有些 DFS 還提供 POSIX 相容檔案系統,讓作業系統 VFS 把它當普通檔案系統。常見整合方式是 FUSE 或 NFS 協議。NFS 可能是最知名分散式檔案系統協議,最初用於讓多個客戶端讀寫單個伺服器上的資料。後來 AWS EFS、Archil 等提供了更可伸縮的 NFS 相容實現。NFS 客戶端雖仍連到一個端點,但底層會與分散式元資料服務和資料節點互動完成讀寫。
分散式檔案系統與網路儲存
分散式檔案系統基於 無共享(shared-nothing) 原則(見“共享記憶體、共享磁碟與無共享架構”),與 NAS(網路附加儲存)和 SAN(儲存區域網路)等 共享磁碟 方案形成對照。共享磁碟通常依賴集中式儲存裝置、定製硬體和專用網路(如光纖通道);無共享方案不要求專用硬體,只需普通資料中心網路互聯的機器。
很多 DFS 構建在商用硬體上,成本更低但故障率高於企業級專用硬體。為容忍機器和磁碟故障,檔案塊通常複製到多臺機器。這也讓排程器更容易均衡負載:任務可在任一持有輸入副本的節點執行。複製可以是多副本(見第六章),也可以是 Reed-Solomon 等 糾刪碼 方案,以更低儲存開銷恢復丟失資料 10 11 12。這與 RAID 思想類似,只是 RAID 面向同一機器上的多塊磁碟,而 DFS 是透過普通資料中心網路跨機器做訪問和複製。
物件儲存
Amazon S3、Google Cloud Storage、Azure Blob Storage、OpenStack Swift 等物件儲存,已成為批處理場景中對 DFS 的主流替代。實際上兩者邊界越來越模糊:正如前一節和“由物件儲存支撐的資料庫”所述,FUSE 可以把 S3 這類物件儲存“掛載成檔案系統”;JuiceFS、Ceph 等系統也同時提供物件 API 與檔案系統 API。但這些介面、效能、以及一致性保證差異很大,即便 API 看似相容,也需要仔細驗證行為是否符合預期。
物件儲存中的每個物件有一個 URL,例如 s3://my-photo-bucket/2025/04/01/birthday.png。其中主機部分(my-photo-bucket)是 bucket 名,後半部分是物件 鍵(key)(示例裡是 /2025/04/01/birthday.png)。bucket 名全域性唯一;物件鍵在 bucket 內必須唯一。
物件讀取用 get,寫入用 put。與檔案系統檔案不同,物件寫入後通常不可變;更新物件需要透過 put 全量重寫,類似鍵值儲存。Azure Blob Storage 和 S3 Express One Zone 支援追加,但多數物件儲存不支援。它也沒有 fopen、fseek 這類檔案控制代碼 API。
物件看起來像按目錄組織,這很容易讓人誤解:物件儲存並沒有真正目錄概念。所謂路徑只是約定,斜槓也是 key 的一部分。這個約定允許你按字首列出物件,類似“目錄列表”,但與檔案系統目錄列舉有兩點不同:
- 字首
list行為更像 Unix 的遞迴ls -R:會返回所有以該字首開頭的物件,包括“子路徑”下的物件。 - 不存在“空目錄”。如果你刪除了
s3://my-photo-bucket/2025/04/01下所有物件,再列s3://my-photo-bucket/2025/04時就看不到01。常見做法是建立 0 位元組物件表示空目錄(如建立空物件s3://my-photo-bucket/2025/04/01以保留目錄佔位)。
DFS 常支援硬連結、符號連結、檔案鎖、原子重新命名等檔案系統操作,而物件儲存通常缺失這些能力:連結和鎖大多不支援;重新命名也非原子,通常是“複製到新 key,再刪除舊 key”。若要“重新命名目錄”,因為目錄名是 key 的一部分,實際上要逐個物件重新命名。
第四章討論的鍵值儲存通常面向小值(通常 KB 級)和高頻低延遲讀寫。相比之下,DFS 和物件儲存通常最佳化的是大物件(MB 到 GB)和低頻大塊讀寫。不過近年物件儲存也在增強小物件高頻訪問能力,例如 S3 Express One Zone 已提供單毫秒級延遲,計費模型也更接近鍵值儲存。
DFS 與物件儲存另一個區別是:HDFS 等 DFS 可把計算任務排程到持有檔案副本的機器上,讓任務本地讀檔案,減少網路傳輸(當任務程式碼遠小於待讀檔案時尤其划算)。物件儲存通常把儲存和計算解耦,雖然可能用更多頻寬,但現代資料中心網路很快,通常可接受。同時這種解耦讓 CPU/記憶體與儲存容量可以獨立擴充套件。
分散式作業編排
前面的“作業系統類比”同樣適用於作業編排。在單機上跑 Unix 批處理任務時,總得有東西真正去執行 awk、sort、uniq、head 程序;需要把一個程序輸出送到另一個程序輸入;要給每個程序分配記憶體;公平排程 CPU 指令;隔離記憶體與 I/O 邊界,等等。單機裡這由作業系統核心負責;分散式環境裡,這就是作業編排器(orchestrator)的職責。
批處理框架會向編排器的排程器發起“執行作業”請求。請求通常包含如下元資料:
- 需要執行的任務數量;
- 每個任務所需記憶體、CPU、磁碟;
- 作業識別符號;
- 訪問憑據;
- 輸入輸出等作業引數;
- 所需硬體資訊(如 GPU、磁碟型別);
- 作業可執行程式碼的位置。
Kubernetes、Hadoop YARN(Yet Another Resource Negotiator)13 等編排器會結合這些請求與叢集狀態,依靠以下元件執行任務:
- 任務執行器(Task executors)
每個節點上執行執行器守護程序,例如 YARN 的 NodeManager 或 Kubernetes 的 kubelet。執行器負責拉起任務、透過心跳上報存活狀態、跟蹤節點上的任務狀態與資源佔用。收到“啟動任務”請求後,執行器會獲取作業程式碼並執行啟動命令;隨後持續監控程序直至結束或失敗,並更新對應狀態元資料。
很多執行器還配合作業系統實現安全與效能隔離,例如 YARN 和 Kubernetes 都會使用 Linux cgroups。這樣可防止任務越權訪問資料,或因資源濫用影響同機其他任務。
- 資源管理器(Resource Manager)
資源管理器維護各節點元資料:可用硬體(CPU、GPU、記憶體、磁碟等)、任務狀態、網路位置、節點健康狀態等,從而形成全域性檢視。其中心化特性可能成為可用性和可伸縮性瓶頸。YARN 藉助 ZooKeeper,Kubernetes 藉助 etcd 儲存叢集狀態(見“協調服務”)。
- 排程器(Scheduler)
編排器通常包含中心化排程子系統,接收啟動/停止作業與狀態查詢請求。例如收到“啟動 10 個任務,使用指定 Docker 映象,且必須執行在某類 GPU 節點上”的請求後,排程器會基於請求和資源管理器狀態決定“哪些任務跑在哪些節點”,再通知執行器執行。
不同編排器命名各異,但幾乎都具備這些核心元件。
Note
有些排程決策需要“應用特定排程器”參與,才能考慮更具體的業務約束,例如當查詢量達到閾值時自動擴容只讀副本。中心排程器與應用排程器協同決定如何執行任務。YARN 把這類子排程器稱為 ApplicationMaster,Kubernetes 通常稱為 operator。
資源分配
排程器在編排系統中最具挑戰的職責之一,就是在資源有限且作業需求衝突時,做出合理分配。它本質上是在公平與效率之間做平衡。
假設一個小叢集有 5 個節點,共 160 個 CPU 核。排程器收到兩個作業請求,每個都想要 100 核。怎麼排最好?
- 可以給每個作業先分 80 個任務,剩餘 20 個等前面的任務結束後再啟動。
- 也可以先跑完其中一個作業,再等 100 核都空出來後跑另一個。這叫 gang scheduling(成組排程)。
- 如果一個請求先到,排程器還要決定是立即把 100 核都給它,還是為未來請求預留一部分資源。
這是很簡化的例子,但已經能看到艱難權衡。以成組排程為例,如果排程器為了湊齊 100 核而長期預留資源,節點會閒置,資源利用率下降,若其他作業也在搶佔式預留,還可能死鎖。
反過來,如果只是被動等 100 核“自然可用”,中間可能被別的作業拿走,導致長時間湊不齊,從而產生 飢餓(starvation)。排程器也可以 搶佔(preempt) 一部分先到作業任務,把它們殺掉給後到作業騰資源;但被殺任務之後還要重跑,整體效率同樣下降。
把這個問題放大到數百甚至數百萬個請求,想求全域性最優幾乎不可行。事實上這是 NP-hard 問題:除了很小規模,很難在可接受時間內算出最優解 14 15。
因此工程上排程器通常採用啟發式方法,在非最優前提下做“足夠好”的決策。常見演算法包括 FIFO、主導資源公平(DRF)、優先順序佇列、容量/配額排程、各種裝箱演算法等。細節超出本書範圍,但這是非常有趣的研究領域。
工作流排程
本章開頭的 Unix 示例是多個命令串聯。分散式批處理中同樣常見:一個作業輸出要成為一個或多個後續作業輸入,而每個作業又可能依賴多個上游輸入。這個依賴結構稱為 工作流(workflow) 或 有向無環圖(DAG)。
Note
我們在“持久化執行與工作流”中討論過“按步驟執行 RPC”的工作流引擎;在批處理語境裡,“工作流”指的是一串批處理過程:每一步讀輸入、產輸出,通常不直接對外做 RPC。持久化執行引擎通常單次請求處理的資料量小於批處理系統,但兩者邊界並非絕對。
需要多作業工作流常見有以下原因:
- 一個作業輸出可能被多個團隊維護的下游作業消費。此時先把輸出寫到公共位置更合理,下游可按“資料更新觸發”或定時方式執行。
- 你可能要在多個處理工具間傳遞資料。比如 Spark 作業寫 HDFS,再由 Python 觸發 Trino SQL 查詢(見“雲資料倉庫”)繼續處理並寫入 S3。
- 有些流水線內部天然需要多階段。例如第一階段按某鍵分片,下一階段按另一鍵分片,那麼第一階段需要先產出符合第二階段要求的資料佈局。
在 Unix 裡,管道用很小的記憶體緩衝連線前後命令,不落盤。若緩衝區滿,上游必須等待下游消費,這是一種 背壓(backpressure)。Spark、Flink 等批處理執行引擎也支援類似模式:一個任務輸出直接傳給下一任務(跨機時經網路傳輸)。
但在工作流中,更常見仍是“上游作業寫 DFS/物件儲存,下游再讀”,這樣可讓作業在時間上解耦。若一個作業有多個輸入,工作流排程器通常會等待所有上游輸入生產成功後再啟動它。
YARN ResourceManager 或 Spark 內建排程器主要做“作業內排程”,不負責整條工作流。為管理跨作業依賴,出現了 Airflow、Dagster、Prefect 等工作流排程器。它們在維護大量批作業時非常關鍵:包含 50~100 個作業的工作流並不罕見;大型組織內很多團隊會跨系統互相消費輸出。沒有工具支撐,很難管理這種複雜資料流。
故障處理
批處理作業往往執行時間長。長時間執行且並行任務多的作業,在執行過程中遇到至少一次任務失敗幾乎是常態。正如“硬體與軟體故障”和“不可靠網路”所述,原因可能是硬體故障(商用硬體尤甚)、網路中斷等。
任務無法完成的另一原因是被排程器主動搶佔(kill)。當系統有多優先順序佇列時,這很常見:低優先順序任務便宜、高優先順序任務昂貴。低優先順序任務可用空閒算力跑,但高優先順序任務一到就可能把它們搶佔掉。雲廠商的對應產品名分別是:AWS 的 spot instances、Azure 的 spot virtual machines、GCP 的 preemptible instances 16。
批處理很多時候對即時性要求不高,因此很適合利用低優先順序資源/搶佔式例項降成本:本質上它在“吃”否則會閒置的算力,提高叢集利用率。但代價是更高的被殺機率:實際裡搶佔往往比硬體故障更常見 17。
由於批處理每次都從頭生成輸出,任務失敗比線上系統更容易處理:刪掉失敗任務的部分輸出,把任務重新排程到別的機器重跑即可。若只因一個任務失敗就重跑整個作業會非常浪費,因此 MapReduce 及其後繼系統都儘量讓並行任務彼此獨立,從而把重試粒度降到單個任務 3。
當一個任務輸出成為另一任務輸入(即在工作流內傳遞)時,容錯更複雜。MapReduce 的做法是:中間資料總是寫回 DFS,且只有寫入任務成功後才允許下游讀取。這個方案在頻繁搶佔環境中也能工作,但會帶來大量 DFS 寫入,效率不高。
Spark 更傾向把中間資料放記憶體或溢寫本地磁碟,只把最終結果寫 DFS;它還記錄中間資料的計算血緣,丟失時可重算 18。Flink 則採用定期檢查點快照機制 19。我們會在“資料流引擎”繼續討論。
批處理模型
前面我們討論了分散式環境中批作業如何排程。現在轉向“批處理框架如何處理資料”。最常見的兩類模型是 MapReduce 與資料流引擎。儘管實踐中資料流引擎已大面積替代 MapReduce,但理解 MapReduce 仍然重要,因為它深刻影響了現代批處理框架。
MapReduce 與資料流引擎都發展出多種程式設計介面:低層 API、關係查詢語言、DataFrame API。它們讓應用工程師、資料分析工程師、業務分析師乃至非技術人員都能參與資料處理。我們將在“批處理用例”中討論這些用途。
MapReduce
MapReduce 的處理模式與“簡單日誌分析”幾乎同構:
- 讀取輸入檔案並切分為 記錄(records)。在日誌例子裡,每條記錄就是一行(
\n為記錄分隔符)。在 Hadoop MapReduce 中,輸入通常存放在 HDFS 或 S3 等物件儲存,檔案格式可能是 Parquet(列式,見“面向列儲存”)或 Avro(行式,見“Avro”)。 - 呼叫 mapper,從每條輸入記錄中提取鍵和值。Unix 示例中 mapper 相當於
awk '{print $7}':URL($7)是鍵,值可留空。 - 按鍵排序所有鍵值對。日誌示例中這一步對應第一次
sort。 - 呼叫 reducer 遍歷排序後的鍵值對。同鍵記錄會相鄰,因此可以在很小記憶體狀態下合併。Unix 示例中 reducer 等價於
uniq -c,統計相鄰同鍵記錄數。
這四步就是一個 MapReduce 作業。第 2 步(map)與第 4 步(reduce)是你寫業務邏輯的地方;第 1 步(檔案切記錄)由輸入格式解析器完成;第 3 步排序在 MapReduce 中是隱式內建的,你無需手寫。這一步是批處理的基礎演算法,我們會在“混洗資料”再討論。
要建立 MapReduce 作業,你需實現兩個回撥:mapper 與 reducer,其行為如下。
- Mapper
對每條輸入記錄呼叫一次。它從輸入記錄中提取鍵和值,並可為每條輸入產生任意數量鍵值對(包括 0 條)。它不保留跨記錄狀態,每條記錄獨立處理。
- Reducer
框架收集 mapper 產生的鍵值對,把同鍵值集合交給 reducer(以迭代器形式)。reducer 可輸出結果記錄(如同一 URL 的出現次數)。
在日誌示例裡,第 5 步還有一次 sort 用於按請求次數排名 URL。MapReduce 若要第二輪排序,通常要再寫一個作業:前一個輸出作為後一個輸入。換個角度看,mapper 的作用是把資料整理成適合排序的形態;reducer 的作用是處理已排序資料。
MapReduce 與函數語言程式設計
MapReduce 雖用於批處理,但其程式設計模型來自函數語言程式設計。Lisp 把 map 與 reduce/fold 作為列表上的高階函式引入,後來進入 Python、Rust、Java 等主流語言。包括 SQL 在內的大量資料處理操作都可在 MapReduce 之上表達。Map 和 reduce 以及函數語言程式設計的一些特性恰好契合 MapReduce:可組合、天然適合資料處理鏈;map 還是典型“令人尷尬地並行”(每條輸入獨立處理);reduce 則可按不同鍵並行。
但用原始 MapReduce API 寫複雜處理其實很費力,例如各種連線演算法都要自己實現 20。MapReduce 相比現代批處理引擎也偏慢,一個重要原因是其“以檔案為中心”的 I/O 讓作業流水化困難:上游不結束,下游很難提前處理輸出。
資料流引擎
為解決 MapReduce 的侷限,出現了多種分散式批處理執行引擎,最著名的是 Spark 18 21 和 Flink 19。它們設計細節各異,但有一個共同點:把整條工作流當成一個作業處理,而不是拆成互相獨立的小作業。
因為它們顯式建模了跨多個處理階段的資料流動,所以稱為 資料流引擎(dataflow engines)。與 MapReduce 一樣,它們提供低層 API(反覆呼叫使用者函式逐條處理記錄),也提供更高層運算元(如 join、group by)。它們透過分片並行輸入,並透過網路把一個任務輸出傳給另一個任務輸入。與 MapReduce 不同,運算元不必嚴格在 map/reduce 兩類角色間交替,而可以更靈活組合。
這些 API 通常以關係風格構件表達計算:按欄位值連線資料集、按鍵分組、按條件過濾、按計數或求和等函式聚合。內部實現依賴的正是下一節要講的混洗演算法。
這種處理引擎風格可追溯到 Dryad 22、Nephele 23 等研究系統。相比 MapReduce,它有幾個優勢:
- 像排序這類昂貴操作只在“確實需要”的地方執行,而不是每個 map 與 reduce 階段之間都預設做。
- 連續多個不改變分片方式的運算元(如 map/filter)可融合成一個任務,減少資料複製開銷。
- 由於工作流裡的連線與資料依賴都顯式宣告,排程器能全域性最佳化資料區域性。比如把“消費某資料”的任務放到“生產該資料”的同機上,用共享記憶體緩衝交換,而非走網路複製。
- 運算元間中間狀態通常放記憶體或本地磁碟即可,比寫 DFS/物件儲存 I/O 更低(後者要多副本並落到多機磁碟)。MapReduce 僅對 mapper 輸出做了這類最佳化,資料流引擎把它推廣到所有中間狀態。
- 輸入一就緒就能啟動下游運算元,無需等待整個上游階段全部完成。
- 可複用已有程序執行新運算元,減少啟動開銷;MapReduce 往往為每個任務起一個新 JVM。
因此,資料流引擎能實現與 MapReduce 工作流同樣的計算,但通常速度明顯更快。
混洗資料
本章開頭的 Unix 工具示例和 MapReduce 都建立在排序之上。批處理系統要能排序 PB 級資料,單機放不下,因此必須使用“輸入與輸出都分片”的分散式排序演算法,這就是 混洗(shuffle)。
混洗不是隨機
“shuffle” 容易引發誤解。洗牌會得到隨機順序;而這裡的 shuffle 產出的是排序後的確定順序,不含隨機性。
混洗是批處理系統的基礎演算法,連線與聚合都依賴它。MapReduce、Spark、Flink、Daft、Dataflow、BigQuery 24 都實現了高可伸縮且高效能的混洗機制以處理大資料集。這裡用 Hadoop MapReduce 的混洗實現做說明 25,但核心思想在其他系統同樣適用。
圖 11-1 展示了一個 MapReduce 作業的資料流。假設輸入已分片,標記為 m1、m2、m3。例如每個分片可以是 HDFS 中一個檔案,或物件儲存中的一個物件;同一資料集的所有分片可以放在同一 HDFS 目錄,或使用同一物件字首。
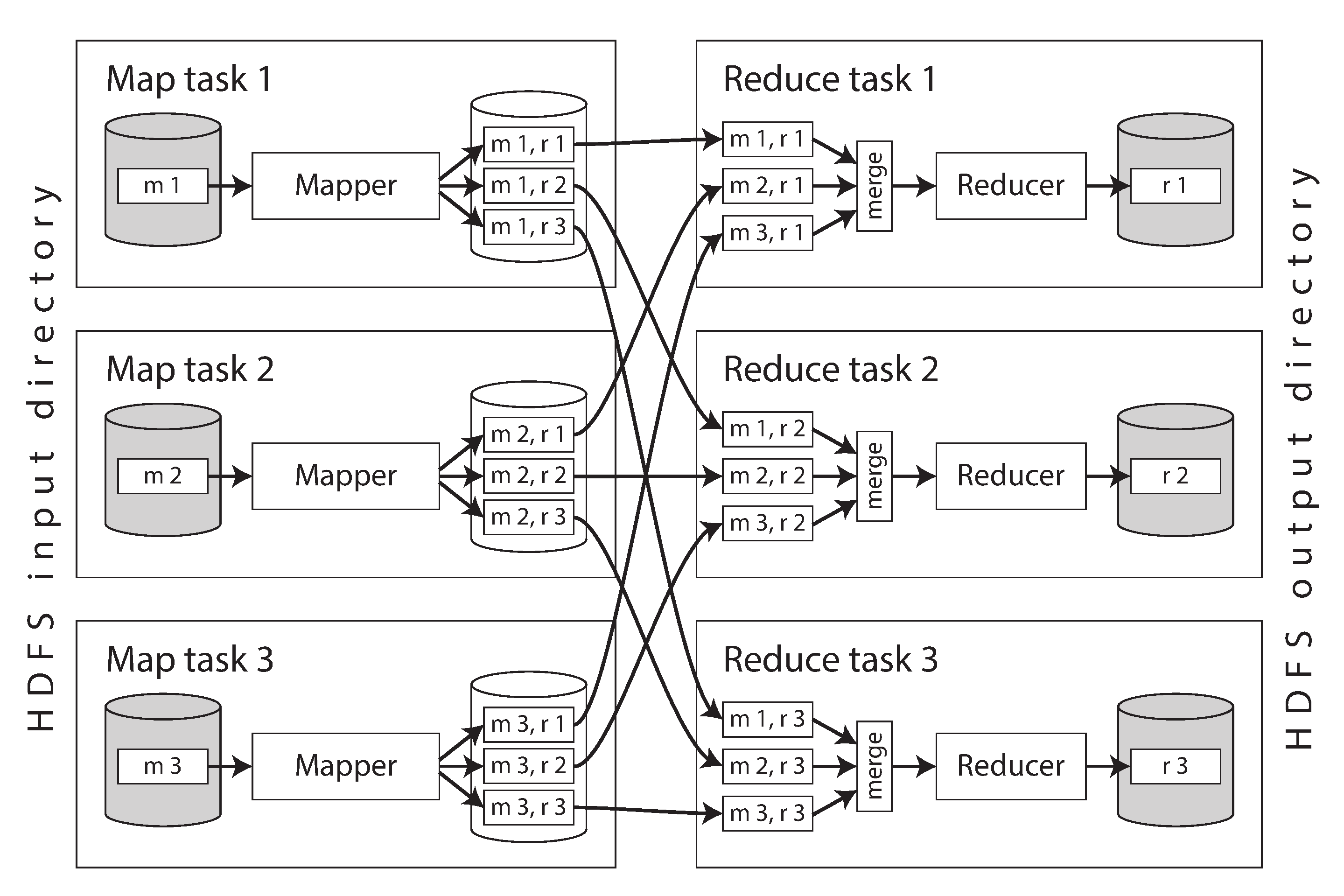
框架會為每個輸入分片啟動一個 map 任務。任務讀取分配到的檔案,並逐條記錄呼叫 mapper 回撥。reduce 側也會分片。map 任務數由輸入分片數決定;reduce 任務數由作業作者配置(可與 map 數不同)。
mapper 輸出是鍵值對。框架需要保證:若不同 mapper 輸出了同一個鍵,這些鍵值對最終必須由同一個 reducer 處理。為此,每個 mapper 會在本地磁碟為每個 reducer 維護一個輸出檔案(例如圖 11-1中的 m1,r2:由 mapper1 生成,目標是 reducer2)。mapper 每輸出一條鍵值對,通常會按鍵的雜湊決定寫入哪個 reducer 檔案(類似“按鍵雜湊分片”)。
mapper 寫這些檔案的同時,也會在每個檔案內部按鍵排序。可用的正是“日誌結構儲存”中的技術:先在記憶體有序結構裡積累一批鍵值對,寫成有序段檔案,再把小段逐步合併成大段。
每個 mapper 完成後,reducer 會連線到 mapper,把屬於自己的有序檔案複製到本地磁碟。reducer 拿到所有 mapper 的對應分片後,再用歸併排序方式合併它們並保持有序。同鍵記錄即便來自不同 mapper,也會在合併後相鄰。隨後 reducer 以“每個鍵一次呼叫”的方式執行,每次拿到一個可迭代器,遍歷該鍵所有值。
reducer 輸出記錄會順序寫入檔案,每個 reduce 任務一個檔案。圖 11-1中的 r1、r2、r3 就是輸出資料集的分片,最終寫回 DFS 或物件儲存。
MapReduce 在 map 與 reduce 之間執行混洗;現代資料流引擎和雲資料倉庫則更複雜。BigQuery 等系統已最佳化混洗,使資料儘量留在記憶體,並寫入外部排序服務 24,以提升速度並透過複製增強韌性。
JOIN 與 GROUP BY
下面看“有序資料”如何簡化分散式連線與聚合。為便於說明仍以 MapReduce 為例,但概念適用於大多數批處理系統。
批處理裡常見連線場景見圖 11-2。左邊是使用者活動日誌(activity events 或 clickstream data),右邊是使用者資料庫。它可以看作星型模型的一部分(見“星型與雪花型:分析模式”):活動日誌是事實表,使用者庫是維度表之一。

如果你要做“結合使用者庫資訊的活動分析”(例如利用使用者出生日期欄位,判斷哪些頁面更受年輕或年長使用者歡迎),就需要連線這兩張表。若兩邊都大到必須分片,怎麼做?
可利用 MapReduce 的關鍵特性:混洗會把同鍵鍵值對匯聚到同一個 reducer,無論它們最初在哪個分片。這裡使用者 ID 就可以作為鍵。因此可寫一個 mapper 掃活動日誌,輸出“按使用者 ID 鍵控的頁面訪問 URL”(見圖 11-3);再寫一個 mapper 按行掃描使用者表,提取“使用者 ID 作為鍵、出生日期作為值”。

混洗保證 reducer 能同時拿到某使用者的出生日期和該使用者全部頁面訪問事件。MapReduce 甚至可以把記錄進一步排成 reducer 先看到使用者記錄、再按時間戳看到活動事件,這稱為 二次排序(secondary sort) 25。
於是 reducer 很容易實現連線邏輯:先拿到出生日期並存入區域性變數,再遍歷同一使用者 ID 的活動事件,輸出“被訪問 URL + 訪問者出生日期”。因為 reducer 一次處理一個使用者的全部記錄,所以記憶體裡只要保留一條使用者記錄,也無需發任何網路請求。這個演算法稱為 排序合併連線(sort-merge join):mapper 輸出先按鍵排序,reducer 再把連線兩側有序記錄合併。
工作流中的下一個 MapReduce 作業就可以繼續計算“每個 URL 的訪問者年齡分佈”:先按 URL 做一次混洗,再在 reducer 中遍歷同 URL 的所有訪問記錄(含出生日期),按年齡段維護計數並逐條累加,從而實現 group by 與聚合。
查詢語言
這些年分散式批處理執行引擎不斷成熟。如今在上萬臺機器的叢集上儲存並處理數 PB 資料,基礎設施已足夠穩健。隨著“如何在這規模下把系統跑起來”基本被解決,重點開始轉向程式設計模型的可用性。
MapReduce、資料流引擎、雲資料倉庫都把 SQL 作為批處理“通用語”。這很自然:傳統資料倉庫本就用 SQL,資料分析/ETL 工具都支援 SQL,幾乎所有開發者和分析師也都熟悉 SQL。
相比手寫 MapReduce,查詢語言介面不僅程式碼更少,還支援互動式使用:可在終端或 GUI 裡寫分析 SQL 並直接執行。這種互動式查詢對於業務分析、產品、銷售、財務等角色探索資料非常高效。雖然它不完全是“經典批處理”形態,但 SQL 讓探索式查詢也能在分散式批處理系統中高效完成。
高階查詢語言不只提升人的生產力,也提高機器執行效率。正如“雲資料倉庫”所述,查詢引擎要把 SQL 轉成在集群裡執行的批處理作業。這個從查詢到語法樹再到物理運算元的轉換過程,讓引擎有機會做最佳化。Hive、Trino、Spark、Flink 等查詢引擎都具備代價最佳化器:它們可分析連線輸入特徵,自動選擇更合適的連線演算法,甚至重排連線順序以減少中間狀態 19 26 27 28。
SQL 是最流行的通用批處理語言,但在一些細分場景中仍有其他語言。Apache Pig 提供了基於關係運算元的逐步式資料流水線描述方式,而非“一個超大 SQL 查詢”。DataFrame(下一節)有相似特徵,Morel 則是受 Pig 影響的更現代語言。還有使用者採用 jq、JMESPath、JsonPath 等 JSON 查詢語言。
在“圖狀資料模型”中,我們討論了圖建模與圖查詢語言如何遍歷邊和頂點。許多圖處理框架也支援透過查詢語言做批計算,例如 Apache TinkerPop 的 Gremlin。我們會在“批處理用例”繼續看圖處理場景。
批處理與雲資料倉庫正在收斂
歷史上,資料倉庫執行在專用硬體裝置上,主要提供關係資料的 SQL 分析查詢;而 MapReduce 等批處理框架強調更高可伸縮性與更高靈活性,允許使用通用程式語言寫處理邏輯,並讀寫任意資料格式。
隨著發展,兩者越來越像。現代批處理框架已經支援 SQL,並藉助 Parquet 等列式格式和最佳化執行引擎(見“查詢執行:編譯與向量化”)在關係查詢上獲得良好效能。與此同時,資料倉庫透過雲化(見“雲資料倉庫”)獲得更強可伸縮能力,並實現了許多與分散式批處理框架相同的排程、容錯和混洗技術,很多也使用分散式檔案系統。
正如批處理系統採納 SQL,雲倉庫也在採納 DataFrame 等替代處理模型(下一節)。例如 BigQuery 提供 BigQuery DataFrames,Snowflake 的 Snowpark 能與 Pandas 整合。Airflow、Prefect、Dagster 等批處理工作流編排器也已廣泛整合雲倉庫。
當然,並非所有批任務都容易用 SQL 表達。PageRank 等迭代圖演算法、複雜機器學習任務都很難用 SQL 寫。涉及影像、影片、音訊等非關係多模態資料的 AI 處理同樣如此。
此外,雲資料倉庫在某些負載上並不理想。行級逐條計算與列式儲存不匹配,效率較低,此時更適合使用倉庫的其他 API 或批處理系統。雲倉庫通常也比其他批處理系統更貴,某些大作業放到 Spark/Flink 等系統可能更具成本優勢。
因此,“用批處理系統還是資料倉庫”最終要看成本、便利性、實現複雜度、可用性等綜合因素。大型企業往往並存多套系統以保留選擇空間;小公司通常一套系統也能跑起來。
DataFrames
隨著資料科學家和統計學家開始用分散式批處理框架做機器學習,他們發現原有處理模型不夠順手,因為他們更習慣 R 與 Pandas 裡的 DataFrame 資料模型(見“DataFrame、矩陣與陣列”)。DataFrame 與關係庫裡的表很像:由多行組成,同一列值型別一致。它不是寫一個超大 SQL,而是透過呼叫對應關係運算元的函式來做過濾、連線、排序、分組等操作。
早期 DataFrame 操作大多在本地記憶體執行,因此只能處理單機裝得下的資料集。資料科學家希望在批處理環境中,仍用熟悉的 DataFrame API 處理大資料。Spark、Flink、Daft 等分散式框架都因此提供了 DataFrame API。需要注意的是,本地 DataFrame 通常帶索引且有順序,而分散式 DataFrame 往往沒有 29,遷移時可能出現效能“意外”。
DataFrame API 看起來和資料流 API 相似,但實現方式差別不小。Pandas 呼叫方法後通常立刻執行;Spark 則會先把 DataFrame API 呼叫翻譯為查詢計劃,做查詢最佳化後,再在分散式資料流引擎上執行,從而獲得更好效能。
Daft 等框架甚至同時支援客戶端與服務端計算:小規模記憶體操作在客戶端執行,大資料與重計算在服務端執行。Apache Arrow 等列式格式提供統一資料模型,可被兩側執行引擎共享。
批處理用例
瞭解了批處理如何工作後,我們來看它在不同應用中的落地。批處理非常適合“海量資料的批次計算”,但不適合低延遲場景。因此,只要資料多且新鮮度要求不高,幾乎都能看到批處理的身影。這聽起來像限制,但現實裡大量工作都符合這個模型:
- 會計對賬與庫存核對:企業定期驗證交易、銀行賬戶與庫存是否一致,常由批處理完成 30。
- 製造業需求預測:通常以週期性批任務計算 31。
- 電商、媒體、社交平臺推薦模型訓練:大量依賴批處理 32 33。
- 許多金融系統也是批處理驅動。例如美國銀行網路幾乎完全基於批任務執行 34。
下面分別討論幾個幾乎所有行業都常見的批處理用例。
提取-轉換-載入(ETL)
“資料倉庫”介紹了 ETL/ELT:從生產資料庫抽取資料、進行轉換,再載入到下游系統。本節用“ETL”統稱這兩類負載。尤其當下遊是資料倉庫時,ETL 常由批處理作業承載。
批處理天然並行,非常適合資料轉換。很多轉換任務都是“令人尷尬地並行”:過濾、欄位投影及大量常見倉庫轉換都可並行完成。
批處理環境通常自帶成熟工作流排程器,便於安排、編排和除錯 ETL 流水線。發生故障時,排程器常會自動重試以覆蓋瞬時問題;若持續失敗,則明確標記失敗,便於工程師快速定位流水線中斷點。像 Airflow 還內建大量 source/sink/query 運算元,可直接對接 MySQL、PostgreSQL、Snowflake、Spark、Flink 等數十種系統。排程器與資料處理系統的緊密整合顯著簡化了資料整合。
我們也看到,批處理在“出錯後排障與修復”方面很友好,這對除錯資料流水線極其關鍵。失敗檔案可直接檢查,ETL 作業可修復後重跑。比如輸入檔案不再包含某個轉換邏輯依賴欄位,資料工程師就能據此更新轉換邏輯或修復上游生產作業。
過去資料流水線往往由單一資料工程團隊集中維護,因為讓產品團隊自行編寫和維護複雜批流水線不太現實。近年隨著處理模型和元資料管理改進,組織內更多團隊都能參與並維護自己的流水線。data mesh 35 36、data contract 37、data fabric 38 等實踐,正透過規範和工具幫助團隊安全釋出可被全組織消費的資料。
如今資料流水線與分析查詢不僅共享處理模型,也常共享執行引擎。很多 ETL 作業與消費其輸出的分析查詢都執行在同一系統裡:例如同樣以 SparkSQL、Trino 或 DuckDB 查詢執行。這樣的架構進一步模糊了應用工程、資料工程、分析工程與業務分析之間的界限。
分析(Analytics)
在“操作型系統與分析型系統”中我們看到,分析查詢(OLAP)通常要掃描大量記錄並做分組聚合。這類負載可以與其他批任務一起執行在批處理系統中。分析人員寫 SQL,經查詢引擎執行,讀寫底層 DFS 或物件儲存。表到檔案對映、名稱、型別等表元資料通常由 Apache Iceberg 等表格式與 Unity 等 catalog 管理(見“雲資料倉庫”)。這種架構稱為 資料湖倉(data lakehouse) 39。
與 ETL 類似,SQL 介面改進讓很多組織用 Spark 等批框架直接承載分析。常見模式有兩類:
- 預聚合查詢:先把資料滾動聚合為 OLAP 立方體或資料集市,以提升查詢速度(見“物化檢視與資料立方”)。預聚合結果可在倉庫查詢,或推送到 Apache Druid、Apache Pinot 這類即時 OLAP 系統。預聚合通常按固定週期執行,通常由“工作流排程”中提到的排程器管理。
- 臨時查詢(ad hoc):使用者為回答具體業務問題、分析使用者行為、排查執行問題等隨時發起。該場景非常看重響應時間,分析師通常會根據每次結果繼續迭代提問。執行快的批處理查詢引擎可顯著縮短等待。
SQL 支援還讓批處理系統更易接入電子表格與視覺化工具,如 Tableau、Power BI、Looker、Apache Superset。比如 Tableau 有 SparkSQL、Presto 聯結器;Superset 支援 Trino、Hive、Spark SQL、Presto 等大量最終會觸發批任務的資料系統。
機器學習
機器學習(ML)高度依賴批處理。資料科學家、ML 工程師、AI 工程師會用批處理框架探索資料模式、做資料轉換、訓練模型。常見用途包括:
- 特徵工程:把原始資料過濾並轉換為可訓練資料。預測模型往往要求數值特徵,因此文字或離散值等資料需要先轉成目標格式。
- 模型訓練:訓練資料是批過程輸入,訓練後模型權重是輸出。
- 批次推理:當資料集很大且不要求即時結果時,可對整批資料做預測,也包括在測試集上評估模型預測效果。
很多框架為這些場景提供了專用工具。例如 Spark 的 MLlib、Flink 的 FlinkML 都內建豐富的特徵工程工具、統計函式與分類器。
推薦系統和排序系統等 ML 應用也大量使用圖處理(見“圖狀資料模型”)。許多圖演算法表達為“沿邊逐步傳播資訊並反覆迭代”:把一個頂點與相鄰頂點連線,傳遞某些資訊,重複直到滿足停止條件,例如無邊可繼續,或某個指標收斂。
批同步並行(bulk synchronous parallel, BSP) 計算模型 40 已成為批圖計算常用模型。Apache Giraph 20、Spark GraphX、Flink Gelly 41 等都實現了它。它也常被稱為 Pregel 模型,因為 Google 的 Pregel 論文讓這一方法廣為人知 42。
批處理同樣是大語言模型(LLM)資料準備與訓練的重要組成部分。網頁等原始文字通常存放在 DFS 或物件儲存中,必須先預處理才能用於訓練。適合批處理框架的預處理步驟包括:
- 從 HTML 中提取純文字,並修復損壞文字;
- 檢測並清理低質量、無關或重複文件;
- 對文字做分詞並轉換為嵌入向量(詞或片段的數值表示)。
Kubeflow、Flyte、Ray 等框架就專為這類負載構建。以 OpenAI 為例,ChatGPT 訓練流程中就使用了 Ray 43。這些框架通常內建與 PyTorch、TensorFlow、XGBoost 等 LLM/AI 庫的整合,並支援特徵工程、模型訓練、批次推理、微調等能力。
最後,資料科學家常在 Jupyter、Hex 等互動式 Notebook 中實驗資料。Notebook 由多個 cell 組成,每個 cell 是一小段 Markdown、Python 或 SQL;按順序執行可得到表格、圖表或資料結果。很多 Notebook 背後透過 DataFrame API 或 SQL 呼叫批處理系統。
對外提供派生資料
批處理常用於構建預計算/派生資料集,如商品推薦、面向使用者的報表、機器學習特徵等。這些資料通常由生產資料庫、鍵值儲存或搜尋引擎對外服務。不論目標系統是什麼,都需要把批處理環境中的 DFS/物件儲存輸出,回灌到線上服務資料庫。
最直觀的做法是:在批作業裡直接使用資料庫客戶端庫,一條條寫生產資料庫(假設防火牆允許)。這雖然能工作,但通常不是好主意,原因有三:
- 每條記錄一次網路請求,比批任務正常吞吐低幾個數量級。即便客戶端支援批寫,效能通常也不理想。
- 批處理框架常並行跑很多工。若所有任務同時以批處理速率寫同一資料庫,很容易把資料庫壓垮,進而影響其線上查詢效能,引發系統其他部分故障 44。
- 批作業通常提供清晰的“全有或全無”輸出語義:作業成功時,結果等價於每個任務恰好執行一次;作業失敗時,無有效輸出。但如果在作業內直接寫外部系統,就產生了外部可見副作用,難以隱藏:部分完成結果可能被其他系統看到,任務失敗重啟還可能造成重複寫。
更好的方案是把預計算結果先推送到 Kafka 這類流系統(我們會在第十二章深入討論)。Elasticsearch、Apache Pinot、Apache Druid、Venice 這類派生資料儲存 45,以及 ClickHouse 等雲數倉,都支援從 Kafka 攝入資料。透過流系統過渡可以改善前述問題:
- 流系統針對順序寫最佳化,更適合批作業的大吞吐寫入模式;
- 流系統可在批作業與生產庫間充當緩衝層,下游可按自身能力限速讀取,避免影響線上流量;
- 一個批作業輸出可被多個下游系統同時消費;
- 流系統還可作為批處理網路與生產網路之間的安全邊界(可部署在 DMZ)。
但“經由流”並不會自動解決“全有或全無”語義。要實現這一點,批作業需要在完成後向下遊發出“作業完成,可對外可見”的通知。流消費者需要像 讀已提交(read committed) 事務那樣,在收到完成通知前讓新資料對查詢不可見(見“讀已提交”)。
另一種在資料庫冷啟動(bootstrap)時更常見的模式,是在批作業內直接構建一個全新資料庫,再把檔案從 DFS、物件儲存或本地檔案系統批次匯入目標資料庫。很多系統都提供這類批次匯入工具,如 TiDB Lightning、Apache Pinot/Apache Druid 的 Hadoop 匯入作業,RocksDB 也提供從批作業批次匯入 SST 的 API。
“批構建 + 批匯入”速度非常快,也更容易在不同資料版本間做原子切換。但對於需要持續增量更新的場景,這種“每次構建全新庫”的方式會更難。很多系統採用混合策略,同時支援冷啟動與增量載入。比如 Venice 就支援混合儲存,可同時做基於行的批更新和全量資料集切換。
本章小結
本章討論了批處理系統的設計與實現。我們先從經典 Unix 工具鏈(awk、sort、uniq 等)出發,說明了批處理的基礎原語,例如排序和計數。
然後我們把視角擴充套件到分散式批處理系統。批處理以“不可變、有限(bounded)的輸入資料集”為物件,生成輸出資料,這使得重跑和除錯可以不引入副作用。圍繞這一模式,批處理框架通常包含三層核心能力:決定作業何時何地執行的編排層,負責持久化資料的儲存層,以及執行實際計算的計算層。
我們看了分散式檔案系統和物件儲存如何透過分塊複製、快取和元資料服務管理大檔案,也討論了現代批處理框架如何透過可插拔 API 與這些儲存互動。我們還討論了編排器在大叢集中如何排程任務、分配資源和處理故障,以及“按作業排程”的編排器與“按依賴圖管理整組作業生命週期”的工作流編排器之間的區別。
在處理模型方面,我們回顧了 MapReduce 及其經典 map/reduce 函式,又介紹了 Spark、Flink 等更易用且效能更好的資料流引擎。為了理解批作業如何擴充套件到大規模,我們重點講了混洗(shuffle)演算法,它是實現分組、連線、聚合的基礎操作。
隨著批處理系統成熟,焦點轉向可用性。高階查詢語言(尤其 SQL)和 DataFrame API 讓批處理作業更易編寫,也更容易被最佳化器最佳化。查詢最佳化器把宣告式查詢轉換為高效執行計劃。
最後我們回顧了批處理常見用例:
- ETL 流水線:透過定時工作流在不同系統間提取、轉換、載入資料;
- 分析:既支援預聚合報表,也支援臨時探索查詢;
- 機器學習:用於準備與處理大規模訓練資料;
- 把批處理輸出灌入面向生產流量的系統:常透過流系統或批次匯入工具,把派生資料提供給使用者。
下一章我們將轉向流處理。與批處理不同,流處理輸入是 無界(unbounded) 的:作業仍在,但輸入是持續不斷的資料流,因此作業不會“完成”。我們會看到,流處理與批處理在一些方面很相似,但“輸入無界”這一前提也會顯著改變系統設計。
參考文獻
Nathan Marz. How to Beat the CAP Theorem. nathanmarz.com, October 2011. Archived at perma.cc/4BS9-R9A4 ↩︎
Molly Bartlett Dishman and Martin Fowler. Agile Architecture. At O’Reilly Software Architecture Conference, March 2015. ↩︎
Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. At 6th USENIX Symposium on Operating System Design and Implementation (OSDI), December 2004. ↩︎ ↩︎
Shivnath Babu and Herodotos Herodotou. Massively Parallel Databases and MapReduce Systems. Foundations and Trends in Databases, volume 5, issue 1, pages 1–104, November 2013. doi:10.1561/1900000036 ↩︎
David J. DeWitt and Michael Stonebraker. MapReduce: A Major Step Backwards. Originally published at databasecolumn.vertica.com, January 2008. Archived at perma.cc/U8PA-K48V ↩︎
Henry Robinson. The Elephant Was a Trojan Horse: On the Death of Map-Reduce at Google. the-paper-trail.org, June 2014. Archived at perma.cc/9FEM-X787 ↩︎
Urs Hölzle. R.I.P. MapReduce. After having served us well since 2003, today we removed the remaining internal codebase for good. twitter.com, September 2019. Archived at perma.cc/B34T-LLY7 ↩︎
Adam Drake. Command-Line Tools Can Be 235x Faster than Your Hadoop Cluster. aadrake.com, January 2014. Archived at perma.cc/87SP-ZMCY ↩︎
sort: Sort text files. GNU Coreutils 9.7 Documentation, Free Software Foundation, Inc., 2025. ↩︎Michael Ovsiannikov, Silvius Rus, Damian Reeves, Paul Sutter, Sriram Rao, and Jim Kelly. The Quantcast File System. Proceedings of the VLDB Endowment, volume 6, issue 11, pages 1092–1101, August 2013. doi:10.14778/2536222.2536234 ↩︎
Andrew Wang, Zhe Zhang, Kai Zheng, Uma Maheswara G., and Vinayakumar B. Introduction to HDFS Erasure Coding in Apache Hadoop. blog.cloudera.com, September 2015. Archived at archive.org ↩︎
Andy Warfield. Building and operating a pretty big storage system called S3. allthingsdistributed.com, July 2023. Archived at perma.cc/7LPK-TP7V ↩︎
Vinod Kumar Vavilapalli, Arun C. Murthy, Chris Douglas, Sharad Agarwal, Mahadev Konar, Robert Evans, Thomas Graves, Jason Lowe, Hitesh Shah, Siddharth Seth, Bikas Saha, Carlo Curino, Owen O’Malley, Sanjay Radia, Benjamin Reed, and Eric Baldeschwieler. Apache Hadoop YARN: Yet Another Resource Negotiator. At 4th Annual Symposium on Cloud Computing (SoCC), October 2013. doi:10.1145/2523616.2523633 ↩︎
Richard M. Karp. Reducibility Among Combinatorial Problems. Complexity of Computer Computations. The IBM Research Symposia Series. Springer, 1972. doi:10.1007/978-1-4684-2001-2_9 ↩︎
J. D. Ullman. NP-Complete Scheduling Problems. Journal of Computer and System Sciences, volume 10, issue 3, June 1975. doi:10.1016/S0022-0000(75)80008-0 ↩︎
Gilad David Maayan. The complete guide to spot instances on AWS, Azure and GCP. datacenterdynamics.com, March 2021. Archived at archive.org ↩︎
Abhishek Verma, Luis Pedrosa, Madhukar Korupolu, David Oppenheimer, Eric Tune, and John Wilkes. Large-Scale Cluster Management at Google with Borg. At 10th European Conference on Computer Systems (EuroSys), April 2015. doi:10.1145/2741948.2741964 ↩︎
Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, and Ion Stoica. Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. At 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI), April 2012. ↩︎ ↩︎
Paris Carbone, Stephan Ewen, Seif Haridi, Asterios Katsifodimos, Volker Markl, and Kostas Tzoumas. Apache Flink™: Stream and Batch Processing in a Single Engine. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, volume 38, issue 4, December 2015. Archived at perma.cc/G3N3-BKX5 ↩︎ ↩︎ ↩︎
Mark Grover, Ted Malaska, Jonathan Seidman, and Gwen Shapira. Hadoop Application Architectures. O’Reilly Media, 2015. ISBN: 978-1-491-90004-8 ↩︎ ↩︎
Jules S. Damji, Brooke Wenig, Tathagata Das, and Denny Lee. Learning Spark, 2nd Edition. O’Reilly Media, 2020. ISBN: 978-1492050049 ↩︎
Michael Isard, Mihai Budiu, Yuan Yu, Andrew Birrell, and Dennis Fetterly. Dryad: Distributed Data-Parallel Programs from Sequential Building Blocks. At 2nd European Conference on Computer Systems (EuroSys), March 2007. doi:10.1145/1272996.1273005 ↩︎
Daniel Warneke and Odej Kao. Nephele: Efficient Parallel Data Processing in the Cloud. At 2nd Workshop on Many-Task Computing on Grids and Supercomputers (MTAGS), November 2009. doi:10.1145/1646468.1646476 ↩︎
Hossein Ahmadi. In-memory query execution in Google BigQuery. cloud.google.com, August 2016. Archived at perma.cc/DGG2-FL9W ↩︎ ↩︎
Tom White. Hadoop: The Definitive Guide, 4th edition. O’Reilly Media, 2015. ISBN: 978-1-491-90163-2 ↩︎ ↩︎
Fabian Hüske. Peeking into Apache Flink’s Engine Room. flink.apache.org, March 2015. Archived at perma.cc/44BW-ALJX ↩︎
Mostafa Mokhtar. Hive 0.14 Cost Based Optimizer (CBO) Technical Overview. hortonworks.com, March 2015. Archived on archive.org ↩︎
Michael Armbrust, Reynold S. Xin, Cheng Lian, Yin Huai, Davies Liu, Joseph K. Bradley, Xiangrui Meng, Tomer Kaftan, Michael J. Franklin, Ali Ghodsi, and Matei Zaharia. Spark SQL: Relational Data Processing in Spark. At ACM International Conference on Management of Data (SIGMOD), June 2015. doi:10.1145/2723372.2742797 ↩︎
Kaya Kupferschmidt. Spark vs Pandas, part 2 – Spark. towardsdatascience.com, October 2020. Archived at perma.cc/5BRK-G4N5 ↩︎
Ammar Chalifah. Tracking payments at scale. bolt.eu.com, June 2025. Archived at perma.cc/Q4KX-8K3J ↩︎
Nafi Ahmet Turgut, Hamza Akyıldız, Hasan Burak Yel, Mehmet İkbal Özmen, Mutlu Polatcan, Pinar Baki, and Esra Kayabali. Demand forecasting at Getir built with Amazon Forecast. aws.amazon.com.com, May 2023. Archived at perma.cc/H3H6-GNL7 ↩︎
Jason (Siyu) Zhu. Enhancing homepage feed relevance by harnessing the power of large corpus sparse ID embeddings. linkedin.com, August 2023. Archived at archive.org ↩︎
Avery Ching, Sital Kedia, and Shuojie Wang. Apache Spark @Scale: A 60 TB+ production use case. engineering.fb.com, August 2016. Archived at perma.cc/F7R5-YFAV ↩︎
Edward Kim. How ACH works: A developer perspective — Part 1. engineering.gusto.com, April 2014. Archived at perma.cc/F67P-VBLK ↩︎
Zhamak Dehghani. How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh. martinfowler.com, May 2019. Archived at perma.cc/LN2L-L4VC ↩︎
Chris Riccomini. What the Heck is a Data Mesh?! cnr.sh, June 2021. Archived at perma.cc/NEJ2-BAX3 ↩︎
Chad Sanderson, Mark Freeman, B. E. Schmidt. Data Contracts. O’Reilly Media, 2025. ISBN: 9781098157623 ↩︎
Daniel Abadi. Data Fabric vs. Data Mesh: What’s the Difference? starburst.io, November 2021. Archived at perma.cc/RSK3-HXDK ↩︎
Michael Armbrust, Ali Ghodsi, Reynold Xin, and Matei Zaharia. Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics. At 11th Annual Conference on Innovative Data Systems Research (CIDR), January 2021. ↩︎
Leslie G. Valiant. A Bridging Model for Parallel Computation. Communications of the ACM, volume 33, issue 8, pages 103–111, August 1990. doi:10.1145/79173.79181 ↩︎
Stephan Ewen, Kostas Tzoumas, Moritz Kaufmann, and Volker Markl. Spinning Fast Iterative Data Flows. Proceedings of the VLDB Endowment, volume 5, issue 11, pages 1268-1279, July 2012. doi:10.14778/2350229.2350245 ↩︎
Grzegorz Malewicz, Matthew H. Austern, Aart J. C. Bik, James C. Dehnert, Ilan Horn, Naty Leiser, and Grzegorz Czajkowski. Pregel: A System for Large-Scale Graph Processing. At ACM International Conference on Management of Data (SIGMOD), June 2010. doi:10.1145/1807167.1807184 ↩︎
Richard MacManus. OpenAI Chats about Scaling LLMs at Anyscale’s Ray Summit. thenewstack.io, September 2023. Archived at perma.cc/YJD6-KUXU ↩︎
Jay Kreps. Why Local State is a Fundamental Primitive in Stream Processing. oreilly.com, July 2014. Archived at perma.cc/P8HU-R5LA ↩︎
Félix GV. Open Sourcing Venice – LinkedIn’s Derived Data Platform. linkedin.com, September 2022. Archived at archive.org ↩︎